

")

why don't you implement raycasting into the environment? so it only renders visible and needed parts. I think this will greatly improve the load times and reduce lag significantly.








Alvajoy123 this is not raycasting. As such, adding a occlusion based on raycasting is harder and much more complex to do, even if it could indeed in theoy help rendering times.
ACagliano : there are various demo's available. If you need the source, it is on github (however, it is not yet C/C++ compatible, but I have recently converted the whole library to be compiled by fasmg instead of spasm and started to clean up the source code. It is on fasmg branch).
ACagliano : there are various demo's available. If you need the source, it is on github (however, it is not yet C/C++ compatible, but I have recently converted the whole library to be compiled by fasmg instead of spasm and started to clean up the source code. It is on fasmg branch).


Finally got around quirks and implemented mip-mapping :
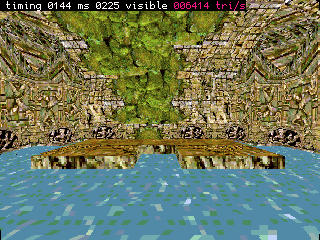
I also optimized quite some part of the library as a part as a full overhaul of the poor rooting code - conversion to fasmg lead only good.
A simple vertex transform stand now at 1600 cycles - or about 30000 vx/s at 48Mhz, which sound more than reasonable
I also optimized quite some part of the library as a part as a full overhaul of the poor rooting code - conversion to fasmg lead only good.
A simple vertex transform stand now at 1600 cycles - or about 30000 vx/s at 48Mhz, which sound more than reasonable



Looking good~!
In my own prototype I manage to get away with this matrix code by limiting the distance any point can be from the player to 8 bit range
Code:
The matrix is stored z row first sequentially for early exit stuff.
Been distracted lately by school, glad to know you've been working on this a lot
In my own prototype I manage to get away with this matrix code by limiting the distance any point can be from the player to 8 bit range
Code:
; Multiplies a vertex by a matrix row
; sp = sp+6
; iy = result
;ix = vertex pointer
;sp = matrix pointer
;hl = return address
; ~300 cycles in fastRam
matrixRowMultiply:
exx
ld iy,0
ld hl,(x)
pop bc
dec sp
ld d,l
ld e,c
ld l,c
ld c,d
mlt hl
mlt de
mlt bc
ld a,d
add a,c
add a,l
ld d,a
add iy,de
ld hl,(y)
pop bc
dec sp
ld d,l
ld e,c
ld l,c
ld c,d
mlt hl
mlt de
mlt bc
ld a,d
add a,c
add a,l
ld d,a
add iy,de
ld hl,(z)
pop bc
dec sp
ld d,l
ld e,c
ld l,c
ld c,d
mlt hl
mlt de
mlt bc
ld a,d
add a,c
add a,l
ld d,a
add iy,de
exx
jp (hl)
The matrix is stored z row first sequentially for early exit stuff.
Been distracted lately by school, glad to know you've been working on this a lot
Glad to hear that you are working on your prototype ! This code is looking great.
I actually have an extended precision for point at -65535,65535 and for matrix at -64,64. The whole matrix * vector is currently standing at ~900 cycles while reading vertex data from flash - but I think there's still some optimisation left (as always !)
The rest of vertex transform is composed of projection, vertex frustrum culling and vertex scissoring. Always wanted to do early z, but this a clipping never let me do it
I actually have an extended precision for point at -65535,65535 and for matrix at -64,64. The whole matrix * vector is currently standing at ~900 cycles while reading vertex data from flash - but I think there's still some optimisation left (as always !)
The rest of vertex transform is composed of projection, vertex frustrum culling and vertex scissoring. Always wanted to do early z, but this a clipping never let me do it
Gotta agree with tr1p -- definitely the most awesome thing I have EVER seen on a CE. I'm working on (read: have thought about starting) a project which is basically PuzzleScript for the CE. Perhaps I could make a generalized 3D version and use this renderer?
Yay one more thing on my plate for me o worry about not finishing...
Yay one more thing on my plate for me o worry about not finishing...
TheMachine02 wrote:
If you need the source, it is on github (however, it is not yet C/C++ compatible...
Any idea on when it might be C/C++ compatible, and/or a libload library, if you plan that at all?
Main issue to resolve to make it properly C/C++ compatible is all the memory shenanigans initally made within the library in order to have full 64K aligned access and other goodies (for exemple, texture space reside in $D30000). And that doesn't play particulary well with countless stuff in the toolchain

Heya TheMachine02 long time no see. Did you have any free time to play around with Virtual3D in recent months?



Register to Join the Conversation
You cannot post new topics in this forum
You cannot reply to topics in this forum
You cannot edit your posts in this forum
You cannot delete your posts in this forum
You cannot vote in polls in this forum
You cannot reply to topics in this forum
You cannot edit your posts in this forum
You cannot delete your posts in this forum
You cannot vote in polls in this forum
Advertisement