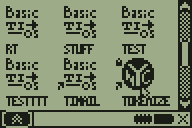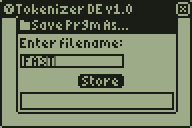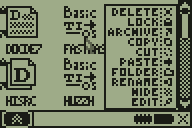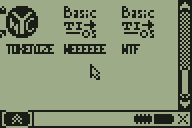
People have been asking for a routine that can tokenize raw oncalc text files (like the files stored by Document DE 7, for instance) into tokenized files (your classic TI-BASIC programs) for years, for possible applications like a custom TI-BASIC editor. I took the first step towards making that a reality today, with a relatively simple brute-force algorithm that uses exhaustive forward-reverse lookup to tokenize plaintext files. The example in the screenshot below uses the DCS GUI API and AP system to open a file containing ':Disp "HELLO Alll', count the tokens to be saved, create a new program, and store the tokenized version. If you watch it, you'll notice two giant sections of lag, the first corresponding to counting the space necessary, the second corresponding to the actual token storage. I'm going to be working on trying to find some optimizations to make, but it's going to be slower than I'd like no matter how I do it. The solution would be a table of tokens in RAM, but that would take many, many KB, and is quite infeasible at this point.
Enjoy, let me know what you can think of to do with something like this, and keep your eye on this topic for improvements and development.

it's too bad about the speed

but this is great

if there was just a small table for like per say, only tokens used by AXE how much more speed do you think you could get? I could supply a list of the tokens if you want too.
Eeems wrote:
it's too bad about the speed
but this is great
Eeems wrote:
if there was just a small table for like per say, only tokens used by AXE how much more speed do you think you could get? I could supply a list of the tokens if you want too.
That would work very nicely, but that would use a much different algorithm. I think that you should try writing that one.
KermMartian wrote:
Thanks! I just checked thoroughly: There's 10 first-byte values for two-byte tokens, and therefore 253 additional tokens, so _get_tok_strng (and _isa2bytetok) are each getting called 253+(254*10) = 2540+253 = 2793 times per token. If I'm careful about specifying what two-byte tokens are legal, I can cut that down to about 700 times per token, roughly four times as fast. I can also write a simple local _Isa2bytetok clone, which should remove lots more overhead. I still have no allusions that it won't be slow, but it won't be this painfully slow.
ah ok, well, that might be the better option.
KermMartian wrote:
That would work very nicely, but that would use a much different algorithm. I think that you should try writing that one.

This implements what I just mentioned, it's definitely a significant speedup:

If I could swap _get_tok_strng's page into ROM Bank 1 during the whole thing, it would help a lot too; I should ask BrandonW if that's feasible.
KermMartian wrote:
This implements what I just mentioned, it's definitely a significant speedup:
http://www.cemetech.net/img/projects/tokenize2.gif
If I could swap _get_tok_strng's page into ROM Bank 1 during the whole thing, it would help a lot too; I should ask BrandonW if that's feasible.
 hopefully it is
hopefully it is
What substring matching algorithm do you use? It seems like a patricia trie with the token values as leaf nodes would be blazingly fast here.
elfprince13 wrote:
What substring matching algorithm do you use? It seems like a patricia trie with the token values as leaf nodes would be blazingly fast here.
Oh, it would, it would be super-fast. However, I'd estimate the raw tokens with no length byte or zero-terminator or token designations as at least 2500 bytes total, so I'm trying to use workarounds that hijack the OS's own routines to make it as if I had a table. In an ideal world I'd do a pass where I generated a tree on-the-fly, then used it, but this is far from an ideal world.
KermMartian wrote:
elfprince13 wrote:
What substring matching algorithm do you use? It seems like a patricia trie with the token values as leaf nodes would be blazingly fast here.
Oh, it would, it would be super-fast. However, I'd estimate the raw tokens with no length byte or zero-terminator or token designations as at least 2500 bytes total, so I'm trying to use workarounds that hijack the OS's own routines to make it as if I had a table. In an ideal world I'd do a pass where I generated a tree on-the-fly, then used it, but this is far from an ideal world.
Out of curiosity, how much space do you have on page 3 of DCS?
elfprince13 wrote:
KermMartian wrote:
elfprince13 wrote:
What substring matching algorithm do you use? It seems like a patricia trie with the token values as leaf nodes would be blazingly fast here.
Oh, it would, it would be super-fast. However, I'd estimate the raw tokens with no length byte or zero-terminator or token designations as at least 2500 bytes total, so I'm trying to use workarounds that hijack the OS's own routines to make it as if I had a table. In an ideal world I'd do a pass where I generated a tree on-the-fly, then used it, but this is far from an ideal world.
Out of curiosity, how much space do you have on page 3 of DCS?Page 0 is 15683 bytes long (701 bytes to spare)
Page 1 is 15862 bytes long (522 bytes to spare)
Page 2 is 15977 bytes long (407 bytes to spare)
I actually just looked through a disassembly of the OS and found that at least 1.19 and 2.41 both have the full table that I need on page 01 of the OS. However, it would be relatively complex for me to find cross-OS-version pointers into the table; I'd need at least three numbers: the start of the one-byte-token table, the end of that slash start of the two-byte-token table, and the end of that.
This seems pretty cool- it reminds me of my project for 68k calcs.
TC01 wrote:
This seems pretty cool- it reminds me of my project for 68k calcs.
Thanks for that, I'm hoping it'll be cool. My main concern is speed, though, unless I bite the bullet and include the -($4800-$5911) = $1111 = 4369 byte table, which doesn't particularly appeal to me.
Initialize the table (or even a full patricia trie) at startup, but have a preference option to cache that to an appvar.
elfprince13 wrote:
Initialize the table (or even a full patricia trie) at startup, but have a preference option to cache that to an appvar.
Eh, I could do that, but I think first I want to just get a proof-of-concept program out the door that does the naive brute-force optimization I wrote thus far. If I let it go full-speed on the 15MHz calcs, it could end up doing 10 tokens in 2 second, or 5 tokens a second, which I consider decent enough for a proof-of-concept.
*illegal 3-hour bump*
Progress bar completed, tokenizer core wrapped in 15MHz mode, look at it go!
It's not great, but it'll do. Notice that there's still a few transcription bugs for me to track down, an About screen to make, and then I'm going to release the first version of this and set it aside for a while so I can focus on DCS 6.9 beta, the manual, and other important things in my life.
Register to Join the Conversation
Have your own thoughts to add to this or any other topic? Want to ask a question, offer a suggestion, share your own programs and projects, upload a file to the file archives, get help with calculator and computer programming, or simply chat with like-minded coders and tech and calculator enthusiasts via the site-wide AJAX SAX widget? Registration for a free Cemetech account only takes a minute.
»
Go to Registration page
You cannot post new topics in this forum
You cannot reply to topics in this forum
You cannot edit your posts in this forum
You cannot delete your posts in this forum
You cannot vote in polls in this forum










: TI Runner-Up")


