
Content Association in Wikipedia
| Category: | Software Projects (back to list) | ||
| Project Page: | Content Association in Wikipedia project page | ||
| Summary: | Wikipedia, the free online encyclopedia, contains a wealth of intellectually and monetarily free content. The sheer number of users editing the corpus means that the majority of the articles are largely factual, but the relationship between related articles, usually inferred by the See Also links at the bottom of each article, are generally incomplete compared to the relationships implied by words linked amidst the text of each article. NLP could provide a unique method of discovering both articles that are related through such correct linking, and that are mutually relevant but insufficiently linked or completely unlinked. | ||
| Complete: |
|
||
| Begin: | April 10, 2010 | ||
| Completed: | May 5, 2010 |
Wikipedia, the free online encyclopedia, contains a wealth of intellectually and monetarily free content (in common terminology, “free as in speech and free as in beer”). The sheer number of users editing the corpus means that the majority of the articles are well-written and largely factual. However, the relationship between related articles, usually inferred by the See Also links at the bottom of each article, are generally incomplete compared to the relationships implied by words linked amidst the text of each article. We propose a PHP framework to spider Wikipedia, collecting both full-text word lists and lists containing only the words from the text of internal links. We propose comparing the relative performance of a system that attempts to find similarity metrics between articles based on the full text of each article and one based on only on the linked words in each article.
The implementation created uses the TF-IDF algorithm to normalize word frequency and the cosine similarity metric to rank article similarity. A sample of the first 8 most similar articles for the full text algorithm (left) and internal link algorithm (right) are shown below. Note that both generate coherent results, but in objective human testing by ten volunteers, the full text method was chosen as producing higher-accuracy results 94% of the time.

A final module in the code renders a visual representation of the relationship between articles known as an "outgraph". The outgraph plots each article as a point in a 2D plane, with more similar articles closer together, and the most similar related articles connected by the boldest segments. Examples for "Laptop" are shown below.
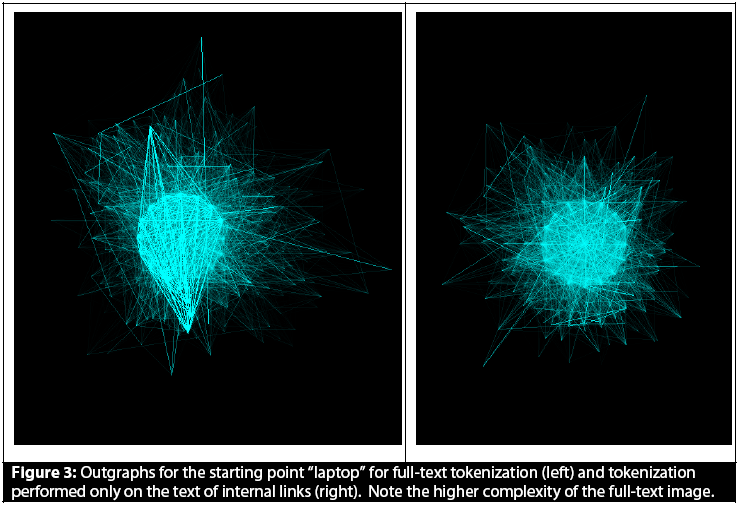
Wikipedia contains many orders of magnitude more articles than were examined in any run of this project, and the internal links method can parse and tokenize at least ten times as fast (1,700 seconds versus 12,000 seconds) as the full text method while using much less memory per article. Therefore, although the full text method produces superior accuracy, a practical application of the system demonstrated in this project might choose speed and efficiency at the expense of a moderate accuracy reduction by implementing the internal links algorithm.
A PDF of the full report for this project can be found below.
 Content Association in Wikipedia
Content Association in Wikipedia
Program Code/Executable
The implementation created uses the TF-IDF algorithm to normalize word frequency and the cosine similarity metric to rank article similarity. A sample of the first 8 most similar articles for the full text algorithm (left) and internal link algorithm (right) are shown below. Note that both generate coherent results, but in objective human testing by ten volunteers, the full text method was chosen as producing higher-accuracy results 94% of the time.
A final module in the code renders a visual representation of the relationship between articles known as an "outgraph". The outgraph plots each article as a point in a 2D plane, with more similar articles closer together, and the most similar related articles connected by the boldest segments. Examples for "Laptop" are shown below.
Wikipedia contains many orders of magnitude more articles than were examined in any run of this project, and the internal links method can parse and tokenize at least ten times as fast (1,700 seconds versus 12,000 seconds) as the full text method while using much less memory per article. Therefore, although the full text method produces superior accuracy, a practical application of the system demonstrated in this project might choose speed and efficiency at the expense of a moderate accuracy reduction by implementing the internal links algorithm.
A PDF of the full report for this project can be found below.
Advertisement